W 2015 i 2016 roku PizzaPortal.pl i Pyszne.pl toczyły zaciętą rywalizację o dominację na rynku dostaw jedzenia online w Polsce. Uber Eats dopiero wchodził na rynek, a inne platformy tego typu jeszcze nie były na horyzoncie.
PizzaPortal, będący częścią DeliveryHero, koncentrowało się na strategii opartej na performance marketingu, inwestując w Google Ads, a ja i optymalizowałem ścieżki zakupową w produkcie. Efektem tego była nowa, szybsza i responsywna strona www oraz natywne aplikacje na iOS i Androida (tutaj zrobiłem dekompozycję tego procesu). Wszystko to znacznie poprawiło naszą konwersję we wszystkich kanałach.
Pomimo to, Pyszne.pl zwyciężyło. Długo zastanawiałem się, dlaczego: mieliśmy lepszy produkt, lepsze targetowanie reklam w internecie, prawdziwy dział obsługi klienta. Jednak przegraliśmy. To była dla mnie frustrująca sytuacja, ponieważ byłem przekonany, że mając lepszy produkt, mamy przewagę. Pyszne.pl było znane z legendarnie słabego procesu zamawiania na www, a ich aplikacja to było tylko przepakowanie strony internetowej do okna przeglądarki. Nie popełniliśmy żadnego błędu, a mimo to przegraliśmy. Dlaczego?
Przez lata zbierałem fragmenty tej układanki – podobne historie i przypadki w innych rynkowych bataliach. Dopiero teraz, 8 lat później, zrozumiałem prawdziwy powód słysząc konwersację Karola (CTO) i Wojtka (PM) w uPacjenta, gdzie obecnie pracuję. Dochodzili do wniosku, że “prawdziwa konwersja dzieje się przed skorzystaniem z produktu”.
Wtedy mi coś kliknęło w głowie. My po prostu błędnie postrzegaliśmy prawdziwą konwersję – to nie jest zdarzenie gdzieś na mapie podróży klienta przez produkt. To nie moment, kiedy klient po raz pierwszy wchodzi bezpośrednio na stronę. To także nie jest moment, kiedy ktoś faktycznie zapłacił za produkt czy usługę. My, produktowcy, lubimy te dwa punkty analityczne, bo są łatwo mierzalne, a to co jest łatwo mierzalne, jest łatwe do raportowania i zrozumienia.
Jednak te liczby są tylko konsekwencją czegoś ważniejszego, czegoś znacznie trudniejszego (lub nawet niemożliwego?) do zmierzenia: prawdziwej intencji. A konkretnie chodzi o moment, kiedy ta intencja się formuje. W większości przypadków (szczególnie jeśli mamy do czynienia z produktem B2C) ten moment pojawia się zanim rozpocznie się mierzalna podróż klienta, a więc zanim klient wejdzie w interakcję z produktem!
Fakt, że klient włączył aplikację, jest efektem tej mentalnej konwersji, a dla całej analityki produktowej to jest tylko pierwszy etap modelowania ścieżki.
Gdy zrozumiałem to, zdałem sobie sprawę, dlaczego Pyszne.pl wygrało. W przeciwieństwie do nas, skupili się na zasięgu: reklamy telewizyjne, billboardy w największych miastach. Zastanawialiśmy się, jakie ogromne budżety musieli na to miesięcznie przeznaczać. Wydawało nam się, że to zły pomysł, bo mając tak słaby produkt, marnują pieniądze i psują pierwsze wrażenie. Dodatkowo, robili coś, co z natury rzeczy jest trudne do policzenia, więc nie mieli jak tego kontrolować, co skutkowało ryzykiem ogromnych strat.
Jednak z mojej nowej perspektywy, ich działania zaczynają mieć sens: uderzali szeroko, w momencie i miejscu formowania się intencji. My natomiast optymalizowaliśmy kilka kroków później na ścieżce użytkownika. W efekcie, pierwszy etap ich lejka konwersji był bardzo szeroki, więc nawet przy słabej „standardowej konwersji”, kończyli z znacznie lepszym efektem.
Jeśli więc prawdziwa konwersja jest tożsama z powstaniem intencji zakupowej, to komunikacja jest ważniejsza od produktu. Natomiast rolą produktu jest praca nad tym, aby nie spieprzyć tego, co komunikacja obiecała. Niemniej mając słaby produkt można wygrać dobrą komunikacją, ale w druga stronę jest to znacznie mniej prawdopodobne.
W pierwszej części notatek o twórczości Eliyahu Goldratta opisałem ideę łańcuchów zależności przez alegorię podróży w góry. W tej części skupie się na bardziej przyziemnym przykładzie: produkcji w fabryce. Dzięki temu możemy sięgnąć po idee, które wychodzą poza pierwotną analogię.
Przyglądając się wystarczająco długo można dojść do wniosku, że każda fabryka ma taką samą logikę: z jednej strony przyjeżdżają ciężarówki z półproduktami, a z drugiej wyjeżdżają z gotowym produktem (nazwijmy go „gadżetem”) na sprzedaż.
Załóżmy, że wiemy, że nasz zakład ma na celu pracować w tempie 5 gadżetów na godzinę. W idealnej sytuacji więc półprodukty wjeżdżają na taśmę, w środku dzieje się „magia” i na koniec do TIRa pakowane jest 5 gotowych gadżetów na godzinę.
Świat idealny
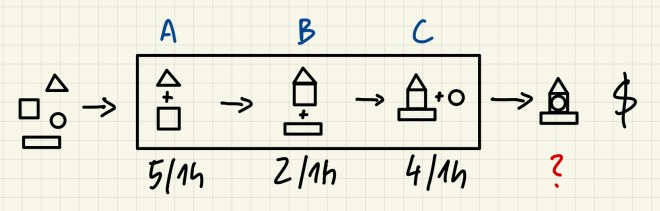
Spójrzmy jednak na to, co dzieje się w środku tej fabryki. Nasz gadżet nie jest składany magicznie – aby spełniać standardy i wymagania klientów musi być złożony w odpowiedniej kolejności kroków. Dla uproszczenia nazwijmy je A, B i C. Każda z tych operacji wymaga specjalistycznego sprzętu, doświadczonych pracowników i naturalnie zajmuje różną długość czasu. Uogólniając jednak można powiedzieć, że łączenie pierwszych częsci zajmuje 12 min, mocowanie drugiej 30 min a dodawanie ostatniej i wypchnięcie do TIRa 15 minut. A więc w ciągu godziny da się wykonać 5 razy krok A, 2 razy krok B i 4 razy krok C.
Skomplikujmy sobie trochę
I teraz pojawia się centralne pytanie i problem: jak szybko będzie pracować fabryka?
Jeśli czytaliście moją ostatnią anegdotę o wycieczce w góry to już wiecie, że mniej niż 5 na godzinę, mniej nawet niż średnia 3 na godzinę.
Załóżmy, że zaczynamy od zera i nie mamy żadnych zapasów (czyli prawie dokończonych gadżetów poukładanych obok stanowiska B lub C).
Po godzinie 1: Stanowisko A: 5, Stanowisko B: 0, Stanowisko C: 0 Po godzinie 2: Stanowisko A: 8, Stanowisko B: 2, Stanowisko C: 0 Po godzinie 3: Stanowisko A: 11, Stanowisko B: 2, Stanowisko C: 2 (wreszcie!)
Ok, mamy 2 produkty na 3 godziny pracy, czyli 1.5 na godzinę. Ale jak to możliwe? Przecież wszystkie maszyny i ludzie pracują na maksymalnych obrotach i średnia z ich pracy to 3 na godzinę? Co tu się stało?
Rozpakujmy ten problem. Po pierwsze zrobiliśmy założenie, że nie mamy jeszcze nigdzie prawie złożonych gadżetów. Ergo, przez pierwszą godzinę pracuje stanowisko A a stanowisko B i C czeka bezczynnie. Po drugie, po godzinie jak już stanowisko A zrobi swoje 5 rzeczy to zabiera się za nie stanowisko B; stanowisko A pracuje już nad kolejnymi, ale stanowisko C ciągle czeka… Stanowisko B po kolejnej godzinie może oddać 2 przedmioty bo tylko taką ma przepustowość, a więc stanowisko C dostaje tylko dwa mimo swojej przepustowości 4 na godzinę (więc pół godziny ludzie stoją tam znudzeni i zamiatają podłogę).
Oczywiście z każdą kolejną godziną ta średnia się poprawi, ale nigdy nie przekroczy magicznej szybkości wąskiego gardła.
Ale czekajcie, to nie wszystko!
Stanowisko A ciągle pracuje pełną parą, więc tworzy nowe przedmioty nawet wtedy kiedy stanowisko B nie może ich przerobić. W związku z tym tworzą się nadwyżki, które trzeba gdzieś magazynować (a to kosztuje!). Fabryka potrzebuje swoich półproduktów, bo jeśli ich nie dostanie to ich najszybciej pracująca ekipa na stanowisku A nie będzie miała co robić (a przecież to niedopuszczalne, bo obniży efektywność kosztową stanowiska!). Więc dział zakupów kupuje więcej półproduktów obniżając wolne środki firmy – te półprodukty też trzeba gdzieś magazynować. Mamy więc dwa sposoby obniżania rentowności organizacji.
Piętrzące się nieefektywności
Stanowisko B robi co może, jeśli mieliby jeszcze bardziej przyśpieszyć to obniży się jakość finalnego towaru, a to spowoduje problemy ze sprzedażą i niezadowolenie na rynku. Tymczasem stanowisko C pracuje na półgwizdka. W pierwsze pół godziny zrobią to co przyjdzie z A i później się nudzą. Kolejne miejsce w którym obniża się rentowność – płacimy ludziom za nic nierobienie a kosztowna maszyna stygnie.
Stanowisko B to tytułowe wąskie gardło. Największa zmora zarządzania jakimkolwiek procesem. Każdy proces ma wąskie gardło i, tak jak pisałem wcześniej: cała wycieczka napije się herbaty z prądem dopiero gdy ostatni jej członek dotrze na szczyt, tak tutaj cały system jest w stanie pracować tak szybko jak jej najwolniejszy element.
Najbardziej fascynujący wniosek Goldratta jest taki, że patrząc na cały system produkcji wąskie gardło nie tylko ogranicza szybkość produkcji ale także powiększa koszty całego systemu. Godzina przestoju wąskiego gardła (incydent) powoduje nie tylko zastopowanie etapu C, ale efektywnie brak powstania dwóch gadżetów! A więc obniżenie efektywności całej fabryki. Tymczasem etap A może sobie robić przerwę częściej niż co drugą godzinę, bo ma nadprodukcję, a etap C i tak pracuje na pół gwizdka bo, za mało dostaje do produkcji. A więc godzina przestoju wąskiego gardła jest najdroższe!
Ale co to wszystko znaczy?
Wąskie gardła są wszędzie. Fabryka to tylko wygodny przykład, ale spójrzcie jak wygląda chociażby dostarczanie nowych funkcji w naszych produktach technologicznych. Gdzie tam są wąskie gardła? Gdzie największe opóźnienia?
O ile podczas wycieczek górskich można najwolniejszego członka przestawić na początek, ale nie da się najpierw opublikować aplikacji mobilnej zanim się ją napisze. Można pracować nad jej zakresem, ale pewna logiczna kolejność, tak jak w fabryce, jest wymagana.
Zapewne intuicyjnie wiecie, gdzie te wąskie gardła są: może to etap zbierania wymagań, design, development, QA a może release management. Zawsze jakieś są, to normalne i nieuniknione ze względu na specyfikę i złożoność pracy.
To, co jednak istotne, to fakt że przyśpieszenie całego cyklu produkcyjnego jest możliwe TYLKO wtedy, gdy wąskie gardło przyśpieszy. Jeśli nie bedziesz nad tym pracować to wygenerujesz dużo nadwyżek (niewykorzystanych designów, zdezaktualizowanego kodu, niespójnych wymagań) i straty czasu całego zespołu.
Prawdopodobnie „najdroższymi” osobami w Twoim zespole są programiści. Wydajemy duże pieniądze, aby przyciągnąć do siebie najlepszych, bo wierzymy, że ich ekspertyza pomoże nam szybciej tworzyć nowe funkcje w produkcie, które ostatecznie pozwolą więcej zarobić firmie. Ale może się okazać, że gdzieś w organizacji jest ktoś wielokrotnie „tańszy”, kto nieświadomie wstrzymuje prace całego zespołu. Jeśli tak faktycznie jest to ta budżetowo „tańsza” osoba jest najbardziej kosztochłonną w całej firmie.
Gratulacje z przeżycia najbardziej nieprawdopodobnego roku w naszej nowożytnej historii! Sami przyznajcie: czy był w Waszym świadomym życiu rok z większą liczbą wydarzeń? W każdym razie w mojej już 9 letniej kronikarskiej karierze (2021, 2020, 2019, 2018, 2017, 2016, 2015, 2014, 2013) ten rok jest zdecydowanie „najciekawszy”.
Gdy już myślałem, że kurz osiadł i możemy rozpocząć odbudowywanie życia po pandemii, to wybuchła wojna tuż za granicą. Znów stolik z mozolnie układanymi puzzlami został przewrócony do góry nogami.
Poniżej najważniejsze puzzle, które w tym roku nie spadły na ziemię.
Ukraina
24 lutego rano dowiedziałem się, że Rosja zaatakowała Ukrainę. Potrzebowałem kilka godzin, aby zrozumieć, co to znaczy. Pamiętam, jak jakiś czas później, siedząc pod prysznicem, spanikowałem. Zacząłem się zastanawiać co zrobić, ile by ode mnie wymagało przetransportowanie się z rodziną do Portugalii na urlop z opcją pracy zdalnej. Następnego dnia staliśmy już w kolejce podobnie myślących ludzi pod urzędem wyrabiając brakujace dowody i paszporty całej rodzinie.
Pamietam, jak wyglądały moje spotkania w pracy i fundacji. Gdzieś, między słowami, ludzi mieli poczucie, że to wszystko co codziennie misternie budują to o kant dupy potłuc, bo zawsze może przyjść jakiś ork z karabinem czy rakietą i wszystko zrównać z ziemią. To jaki jest sens?
Mieszały mi się w głowie różne emocje. Z jednej strony poczucie szczęścia, że jestem po tej bezpiecznej stronie granicy, z drugiej przebłyski paniki, że to poczucie bezpieczeństwa jest iluzoryczne. Z innej wkurwienie na ludzi, którzy uważają, że mogą w imię jakichkolwiek idei podpisywać się pod mordowaniem innych, smutek myśląc o tych wszystkich przerażonych uchodźcach. Do tego dochodziło zmęczenie – przecież dopiero co odbiliśmy się od dna z COVIDem, a teraz kolejny kryzys.
Jednocześnie łapałem się małych promieni światła: spontanicznych akcji jak gdy TIR z owocami i warzywami, jadący do kijowskiego supermarketu zatrzymał się na Wilanowie, bo właściciele stwierdzili, że lepiej będzie wszystko sprzedać w Polsce, a za te pieniądze zawieźć materiały medyczne na front. To było piękne jak oddolnie wszyscy się zorganizowali i wykupili cały towar.
Jakiś czas później postanowiliśmy z Pauliną mocniej się zaangażować i dodaliśmy nasze miejsce do bazy tymczasowych noclegów dla uciekających rodzin. Jako pierwsza trafiła do nas rodzina z Zaporoża: mama z dwójką synów i kotem. Jechali 6 dni aby dotrzeć do Polski, opowiadali o lejach bombowych w drogach, samochodach w rowach i strachu jak im towarzyszył.
Kilka dni później trafiła do nas mama z 10letnią córką z okolic Kijowa. Podczas alarmu bombowego schowali się w metrze i dostali możliwość ewakuacji. Mając tylko jedną torebkę skorzystali z okazji zostawiając wszystko za sobą (tata nie mógł, bo został powołany do służby). Pokazywali nam zdjęcia z wakacji, wspólne wycieczki i imprezy rodzinne – wtedy do nas dotarło, że ta rodzina jest zupełnie taka jak my. Równie dobrze to Paulina mogła tak uciekać z naszymi dziećmi na Zachód.
Poczułem się krucho.
Normalizacja normalizacji
Z każdym następnym tygodniem Rosjanie obrywali coraz mocniej. Strach ciągle był, ale idea niezwyciężonej rosyjskiej armii i geniuszu Putina się ulotniła. Łatwiej więc było sobie znormalizować sytuację, w ten sam sposób jak dziesiątki tysięcy ludzi umierających na COVID w 2021 roku.
Życie toczy się dalej. Trzeba funkcjonować, mimo dziesięciu miesięcy konfliktu tuż za naszą granicą. Jeść obiady, chodzić do pracy, jeździć na wakacje. Układać te puzzle jeden po drugim. Za każdym razem zaskakuje mnie jak elastyczni są ludzie w dostosowywaniu się do sytuacji. Jesteśmy prawdziwymi maszynami do adaptacji.
4 lata inwestowania
W 2018 zrobiłem pierwsze kroki inwestycyjne za namową mojego przyjaciela Przemka Gershmanna. Dałem sobie wtedy 4 lata, żeby ocenić efekty – teraz czas to sprawdzić.
Jest wiele sposobów, aby liczyć skuteczność inwestycji i ka`żdy ma jakąś swoją wadę. Poniżej jeden, który mi się wydaje najprzyjaźniejszy: „Ile obecnie warte jest moje pierwotnie zainwestowane hipotetyczne 10 tys dolarów”. Odpowiedź: prawie 15 tys dolarów. To daje 10% corocznego zwrotu. Dużo? Mało? Nie wiem, ale dla mnie wystarczająco bo pierwotnie wychodziłem z założeniem 6% rok do roku.
W tym czasie natomiast dużo się zadziało:
3 miesiące po moich debiucie (kupiłem CDProjekt i ETF SP500) zaczął się krach 2018/2019. W skrajnym momencie byłem 10% pod wodą. Całkiem niezły początek przygody, co?
2019 był bardzo łaskawy, niemal nieprzerwany rajd w górę, w którym dostarczałem nowej gotówki i kupowałem szeroki rynek. Wszystko pięknie rosło, nawet pod koniec roku, gdy zaczęły pojawiać się pierwsze sygnały o jakimś tajemniczym wirusie…
I wreszcie balonik pękł w połowie marca 2019. Patrzyłem z niedowierzaniem jak wszystkie indeksy pokazują się na czerwono a moje zyski wyparowały,
Z równie wielkim niedowierzaniem obserwowałem, co działo się dalej. Silny spadek był preludium do jeszcze większego rajdu w górę. Ja w ten rajd długo nie wierzyłem i to był mój (do tej pory) największy błąd,
Cieszyłem się jednak z akumulowanych przez te dwa lata akcji CDProjektu, które w grudniu 2020 przebiły 400zł/sztukę z okazji ciśnienia związanego z Cyberpunkiem. Dla mnie to już była przesada, więc po raz pierwszy zrobiłem prawdziwą redukcję portfela,
Miałem szczęście początkującego, bo kilka dni później CDP spadał aż do połowy wartości z 2022 (co wykorzystałem na powolne uzupełnianie, aby obniżyć sobie średnią cenę zakupu),
Największy portfel miałem na początku stycznia 2022, ale już w lutym zdecydowałem się zlikwidować 2/3 z niego i przeznaczyć na inną inwestycję,
I znów miałem szczęście, bo udało mi się dosłownie dni przed ogólnorynkową korektą pocovidową (a to jeszcze było przed agresją Rosji w Ukrainie)
Jak oceniam 4 lata inwestowania? Przede wszystkim muszę powiedzieć, że się myliłem: pierwotnie bałem się, że giełda to ruletka, która mnie wciągnie jak hazard. Możliwe, że tak może działać na innych, ale ja czuję się z giełdą kompatybilny – nie mam problemu z czekaniem i akumulowaniem. Nie czuję potrzeby szybkich ruchów i nie chcę walczyć z nudą. Filozoficznie pasuje mi najbardziej podejście Charliego Mungera: „kup i siedź na dupie”.
A na co poszły pieniądze ze zlikwidowanego portfela? Na wkład własny do kredytu hipotecznego.
Ja, rentier?
Rok temu pisałem, że rozważam pozagiełdowe inwestycje. Wtedy już byliśmy na etapie przyznanego kredytu hipotecznego, ale nie chciałem niczego zapeszać.
Moja rodzina i znajomi drapali się za głowę, gdy dowiedzieli się, że biorę kredyt na zakup mieszkania. Przez te wszystkie lata im przecież mówiłem, że nie chcę mieć na sobie tego ciężaru, a tymczasem ich tak zaskakuję.
To była jedna wyjątkowa okazja. Właściciele to nasi dobrzy znajomi, którzy wyprowadzają się poza miasto, znamy dobrze okolicę, znamy mieszkanie, mocno czujemy jego potencjał jako nieruchomość do wynajęcia i wiemy o nim zanim jeszcze trafi na szeroki rynek. Wygląda na to, że mogę tutaj zagrać w przyjemną grę, gdzie asymetria informacji jest po naszej stronie. Właśnie takie sytuacji szukałem, aby przechylić moje negatywne podejście do kredytu. Działaliśmy szybko, gdy zrozumieliśmy, że to dobry pomysł, a i tak cały formalności zajął nam 6 miesięcy.
Oczywiście inflacja w nas mocno uderzyła, ale już na etapie wyliczeń zakładałem, że musimy się przygotować na dwukrotnie wyższe raty. Skok stóp procentowych z 0.5% na ponad 6.5% i do tego inflacja z 4% na 18% nie była dla nas katastrofalny (ale tak czy inaczej ciągle mocno boli). Jeśli jednak patrzy się na perspektywę 20+ lat to uspokaja myśl, że te stopy będą się zmieniać jeszcze tyle razy, że ta obecna inflacja stanie się niemiłym wspomnieniem.
Razem z Pauliną mieliśmy pewną hipotezę inwestycyjną: chcieliśmy, żeby nasze mieszkanie na wynajem było przyjazne dla rodzin z dziećmi i zwierzętami (co w każdym podręczniku inwestora jest traktowane jako błąd). W efekcie warszawski rynek jest zalany metrażowo zoptymalizowanymi kawalerkami, które wyglądają super w Excellu i nie nadają się do prawdziwego życia. Poszliśmy pod prąd i w naszym anegdotycznym przypadku było warto – znaleźliśmy fajnych lokatorów już po tygodniu od puszczenia ogłoszenia.
Urlopowanie razem i osobno
W długi weekend majowy otworzyliśmy sezon urlopowy naszym campervanem wyprawą na wyspę Wolin. Przekraczając dumny znak mówiący że jesteśmy na wyspie to w sumie… nic się nie zmieniło. Nijak nie dało się odczuć, że jesteśmy na wyspie. Nie tak sobie to wyobrażałem w 6 klasie podstawówki na geografii! Niemniej sama możliwość pokazania po raz pierwszy Morza Bałtyckiego naszej córce, tak jak 4 lata wcześniej synowi to było miłe doświadczenie.
Pierwsze spotkanie córki z Morzem Bałtyckim
Nasz długi urlop zaczęliśmy pod koniec czerwca. Pierwszy etap to powolna podróży w stronę Beskidu Żywieckiego, nocując po drodze w okolicy Częstochowy.
Skalny labirynt w Błędnych Skałach
Następnie spędziliśmy tydzień w schronisku PTTK Przysłop, gdzie dzieci miały kolonie w trybie „razem ale osobno”: razem się spało, a później dzieci były porywane na serię tułaczek po lesie, budowy szałasów i przepraw przez strumyki. Z dala od miasta, ulic i samochodów dzieci szybko przechodzą w swój „dziki” styl życia: bieganie po polanach, kąpanie się w zimnej wodzie i walki na patyki.
W drugim tygodniu zjechaliśmy na dół do cywilizacji i później na zachód wzdłuż gór i w stronę Wrocławia.
Okolice Warszawy
Na koniec wspólnego urlopu skoczyliśmy na last minute na Korfu, pobyć trochę sami i odpocząć od dzieci. To w sumie był mój pierwszy raz na all inclusive – poczułem co to znaczy sączyć (prawie bezalkoholowe) piwko w basenie.
Sezon zakończyliśmy wspólnym wypadem w cudowne okolice Olsztynka z naszymi kamperowymi znajomymi
Wspólnie i osobno
Naszym tegorocznym odkryciem były escape roomy. Zwiedziliśmy przez ostatni rok zarówno takie dla dorosłych (Powstanie Warszawskie, Katakumby) ale także dziecięce. Ciekawe jest to, że w Polsce mamy bardzo aktywną społeczność escaperoomowców, którzy umawiają się w całej Polsce na wspólne ich rozwiązywanie.
To, co Escape Roomy nam uświadomiły, to fakt, że ja i Paulina mamy zupełnie inaczej poukładane głowy. Ta neuroróżnorodność powoduje że dobrze się zgrywamy: ona łączy kropki, ja analizuje fakty. Ja idę od ogółu do szczegółu, ona odwrotnie. Świetnie się zgrywamy w takim zamkniętych przestrzeniach, w której celem jest dotarcie do mety.
Kontynuuję też moją tradycję wolnych czwartków. W ciągu tego roku miałem kilka projektów, którymi sobie je wypełniałem: jednym z nich było odwiedzenie wszystkich studyjnych kin w Warszawie, innym (obecnym) było przejście przez cały kurs nocode’u kupiony optymistycznie ponad rok temu.
Książki
To nie był dobry rok jeśli chodzi o czytanie książek. Finalnie nawet nie udało mi się dociągnąć do jednej książki na miesiąc, ale za to mam dużo rozpoczętych i nie skończonych pozycji (tutaj mój przegląd na Goodreads).
Dlaczego tak się stało? Było wiele powodów: mniej się przemieszczam po mieście więc mam mniej słuchania audiobooków. Poza tym czuję, że mój mózg znowu zaczął się odzwyczajać się od czytania papieru (zbyt szybko traci koncentrację). Powrót do papieru jest jak trening siłowy.
Niemniej dwie książki jednak szczególnie chciałbym wyróżnić. Pierwsza z nich to „Leviathan Falls” – dziewiąta, finałowa część serii Expanse. Ah, co to był za wspaniały świat, co za wielowymiarowe postaci i skala wydarzeń rozciągnieta na kosmologiczną skalę! Wychodzi na to, że przejście przez te wszystkie dziewięć części zajęło mi 4 lata. Ostatnia część dała mi to, czego potrzebowałem: mądre, nieśpieszne zakończenie. Oraz ogromny smutek że to już koniec.
Druga książka pochodzi z zupełnie innego obszaru: „Courage to be disliked”, o której już wspominałem w 2021. To światopoglądowy walec. Jest tam wiele interesując idei, ale najciekawsza dla mnie to myślenie wertykalne i horyzontalne. Ludzie myślący wertykalnie uważają, że są w ciągłej walce o status i pozycję w hierarchii. Ich cel to bronić swojej pozycji przed tymi niżej i ściągać w dół tych wyżej. W tym samym paradygmacie rozwijają się ich związki osobiste i rodzinne. Ludzie myślący horyzontalnie zakładają, że wszyscy są równi przez sam fakt istnienia. Jedyna droga do przodu jest możliwa, jeśli wszyscy ruszamy się do przodu. Nie trudno jest zobaczyć, kto z tych perspektyw jest psychologicznie i społecznie zdrowsza.
Misja na 2022: wytrenować znów mięsień czytania papierowych książek.
Gra w rodziców i dzieci
W tym roku mieliśmy podwójny kamień milowy: nasze młodsze dziecko poszło do przedszkola, a starsze do szkoły. To znów przewróciło do góry nogami rodzinną logistykę i jeszcze nie osiągnęliśmy domowej homeostazy.
Nasze dni są ciężke. Nie mamy buforów, bardzo łatwo cały nasz rodzinny domek z kart może przewrócić byle powiew zmiany w kalendarzach. Ta ciągła niepewność i konieczność bycia w kilku miejscach jednocześnie drenuje energetycznie i emocjonalnie. Oby to było warte swojej ceny.
Słuchając po raz któryś już zebranych wykładów Alla Wattsa trafiłem na moment o roli rodziców. Najpierw powinni skrupulatnie uczyć swoje dzieci grać w grę jakim jest życie: relacje, interakcje, komunikacje, kooperacje, konsekwencje – mają zrozumieć zasady, żeby szybko stanąć ma swoich społecznych nogach.
Ale! Przychodzi moment, gdy rola rodziców się zmienia i istotne staje się coś innego: uświadomienie dzieciom, że to wszystko to właśnie tylko gra. Ona odbywa się w naszych kolektywnych głowach. Nie da się w nią wygrać, bo zawsze jest ktoś wyżej, ktoś to ma więcej. Można jej stawić czoła dopiero jak się zrozumie, że nie ma sensu traktować jej poważnie.
To jeszcze nie jest nasz moment, ale boję się, że nadejście wcześniej niż się spodziewam – bo ja sam nie potrafię tej gry przestać traktować serio. Jak więc móglbym nauczyć tego moje dzieci?
Nowa praca
Po urlopie rozpocząłem nową pracę w startupie uPacjenta założonego przez Dominika Swadźbę i Konrada Kargola. Samą usługę poznałem jeszcze w 2021, gdy odbilismy się od problemu pobrania krwi naszym dzieciom. Było to absolutnie niewykonalne w przychodni czy punkcie ze względu na stres i strach jakie wywoływały u dzieci.
Wtedy Paulina znalazła możliwość pobrania w domu właśnie dzięki uPacjenta. Pamiętam, że napisałem wtedy do Konrada, że uPacjenta robi fantastyczną robotę – nie da się opisać o ile lepiej jest mieć pobraną krew w domu, nawet dla dorosłego. To transformative experience.
Nie zmieniłem pracy ponieważ w poprzednim miejscu było mi źle. Wręcz przeciwnie: DobryMechanik dalej świetnie się rozwija. W uPacjenta jednak czuję, że mogę robić coś osobiście dla mnie ważnego. Zmniejszać ból, którego sam doświadczyłem. To zupełnie inny zestaw motywacji.
Paulina lubiła mi dogryzać przez ostatnie lata, że moje umiejętności powinny być wykorzystane na coś ważniejszego niż rozwożenie pizzy, zamawianie taksówek czy naprawy samochodów. Pokazywała mi jak dużo jeszcze jest do zrobienia tam, gdzie są „prawdziwe” problemy, jak w jej ulubionej branży ochrony zdrowia.
No to jestem. I plany mam ambitne.
Przynależność
Czasami myślę o moich potrzebach jak o baterii, które trzeba napełniać. Mam potrzebę ciszy i czasu dla siebie – żeby poczytać i pofilozofować. Mam potrzebę robienia sensownych rzeczy, które wnoszą innym ludziom wartość w życiu. Ale praca zdalna przyniosła mi nową potrzebę, lub odkryła taką, o której nie miałem pojęcia: potrzebę przynależności.
Lubię pracę zdalną, jak zapewne każdy introwertyk. Mój problem z nią polega jednak na tym, że zacząłem przez nią czuć samotność. Rozmawianie z ludźmi na płaskim ekranie nie ma tej samej „rozdzielczości” jak na żywo. Gdy siedzi się większość dnia przed płaskim ekranem to ciężko budować poczucie przynależności – do grupy czy idei.
Pracując w biurze spontaniczne spotkania i rozmowy dzieją się naturalnie. Pracując w domu trzeba je sobie samemu zorganizować, a to wymaga dodatkowej energii.
Ale to nie tylko przynależność do ludzi, to także przynależność do czegoś większego: życia, natury, idei. Ciągle coś robiąc, przemieszczając się z miejsca w miejsce, dążenie do kolejnego celu zaciemnia to poczucie po prostu „bycia”.
Jeden z lepszych moich momentów w roku. Cały dzień siedziałem na werandzie, dzieci biegały po działce, przychodzili jedni ludzie, wychodzili inni. Nigdzie nie musiałem się śpieszyć. Lubie tak.
Siła i waga
To rok największego progresu mojej formy po katastroficznych latach pandemii. Kontynuowałem pracę nad siłą rozpoczęte w 2021 dochodząc do absurdalnych wyników (z perspektywy początków). Przebijałem cele jeden za drugim.
Okazało się że realne jest osiągnięcie 500 kilogramów w trójboju siłowym (suma rekordów z martwego ciągu, przysiadu ze sztangą i wyciskania na ławce). Faktycznie czułem się silny, z czego zdawałem sobie sprawę przy błahych okazjach jak przenoszenie mebli czy przemieszczenia się będąc obwieszonym dwoma bąbelkami.
Finalnie dotarłem do 455kg i faktycznie czułem że cel jest w zasięgu wzroku. Miałem jednak w planach jeszcze jeden cel: chciałem sprawdzić, czy faktycznie Intermittent Fasting jest uwagi.
IF zadziałało na mnie bardo dobrze (spadło mi ponad 10% wagi), ale efekt uboczny jest taki, że wraz ze spadkiem wagi spadła mi też siła. Teraz mozolnie próbuje zrównoważyć jedno z drugim.
W każdym razie w swoim życiu próbowałem już wielu systemów i diet i każda z nich miała w sobie wbudowany deal breaker: trzeba o niej pamiętać. Narzut pamiętania o tym co wolno a czego nie wolno… a do tego jeszcze liczenie kalorii. W dłuższej perspektywie to bardzo trudne to kontrolowania, szczególnie po całym dniu intelektualnego wysiłku.
Dlatego takim odkryciem było dla mnie IF: wystarczy zrezygnować ze śniadania i kolacji. Cała reszta to przypisy. Na początku było trudno, ale potrzebowałem tygodnia, aby się mentalnie przestawić. Później zobaczyłem, że to wręcz łatwiejsze niż moja dotychczasowy nie-system , bo rezygnując ze śniadania zyskuje sporo czasu rano i ograniczam liczbę podejmowanych decyzji o tym, co mam zjeść. Szczegółowo o IF rozpisał się Michał Sadowski tutaj.
Podsumowując
To był męczący rok. To był rok błyskawicznego przerażenia i podskórnego strachu. To był rok postępu i początku wątpienia w progres. To był rok nowych początków i konsekwencji. To był rok wielu wydarzeń i znurzenia. To rok, w którym było dużo dobrym lokalnych wiadomości, które toneły w globalnych problemach. To był rok bez wspólnego mianownika.
Gdzieś w środku wierzyłem, że jak już wynurzymy się covidowej zawieruchy będziemy mieć nowe otwarcie, nową rzeczywistość do zagospodarowania. Tymczasem dostaliśmy w nagrodę nowe problemy. A może zawsze tak było tylko mój wewnętrzny radar był nastawiony na inne rzeczy?
To był pierwszy rok, w straciłem swoją dotychczas niezachwiany optymizm co do przyszłości. W tym roku już nie czułem, że „będzie już tylko lepiej”. Nie wiem czy to kwestia mojej zmiany związanej z wiekiem (czy to już kryzys wieku średniego?) czy obiektywna sytuacja, ale martwiłem się w tym roku bardziej niż zwykle.
Dwa lata pandemii, która płynnie przeszła w wojnę za naszą granicą przekierowały mój mózg na to, co mogę stracić zamiast na to, co mogę zyskać z czasem. Na początku tego wpisu napisałem, że znów ktoś mi przewrócił stolik z puzzlami. Ale to nie jest precyzyjne: Ja się boję, że patrząc jak inne stoliki obok się wywracają przyjdzie też czas na mój. A im więcej mam ułożonych puzzli, tym bardziej się boję.
Nie lubię tej perspektywy i chcę przeznaczyć kolejny rok, aby coś z tym zrobić.
To co mnie podtrzymuje przy duchu to świadomość, że „to też minie”, a po trudnych przeżyciach przychodzi nie tylko stres, ale także wzrost.
Niemniej: przydałby się rok jak za dawnych lat, kiedy nic się nie działo. Komu to przeszkadzało?
Pozostawiam Was z myślą na 2023 z kalendarza Loesje